How a platform-led approach transforms repetitive firefighting into strategic, system-wide reliability for modern plants.
The Groundhog Day effect in reliability engineering isn’t just hearsay; it’s a reality in many plants, where teams are often trapped fighting unplanned asset failures instead of preventing them. And the cost of this cycle, including unplanned downtime, bleeds the industry’s bottom line, with an estimated $50 billion loss per year [source: teamsense.com], with the average manufacturer facing ~800 hours of downtime annually. Studies by McKinsey also estimated that unplanned downtime of critical assets can cost companies as much as $260,000 per hour. Furthermore, workforce morale suffers and burnout looms due to recurring unexpected breakdowns, which also require additional support from external SME consultants.
Solution?
Early predictive maintenance solutions promised to break this cycle, but they have failed. Over the years, many heavy industrial giants have invested millions in predictive maintenance software and condition-monitoring tools, hoping to get ahead of failures finally. However, too often, these tools became a source of frustration in themselves. They would throw up anomaly alerts with no context or require engineers to toggle between separate systems to piece together what was happening. Even engineers with decades of experience on the plant floor have to juggle between vibration monitoring apps, thermal imaging reports, CMMS/EAM systems, and numerous Excel sheets or sensor trends, yet still miss the root cause of failures or standalone predictive maintenance alerts.
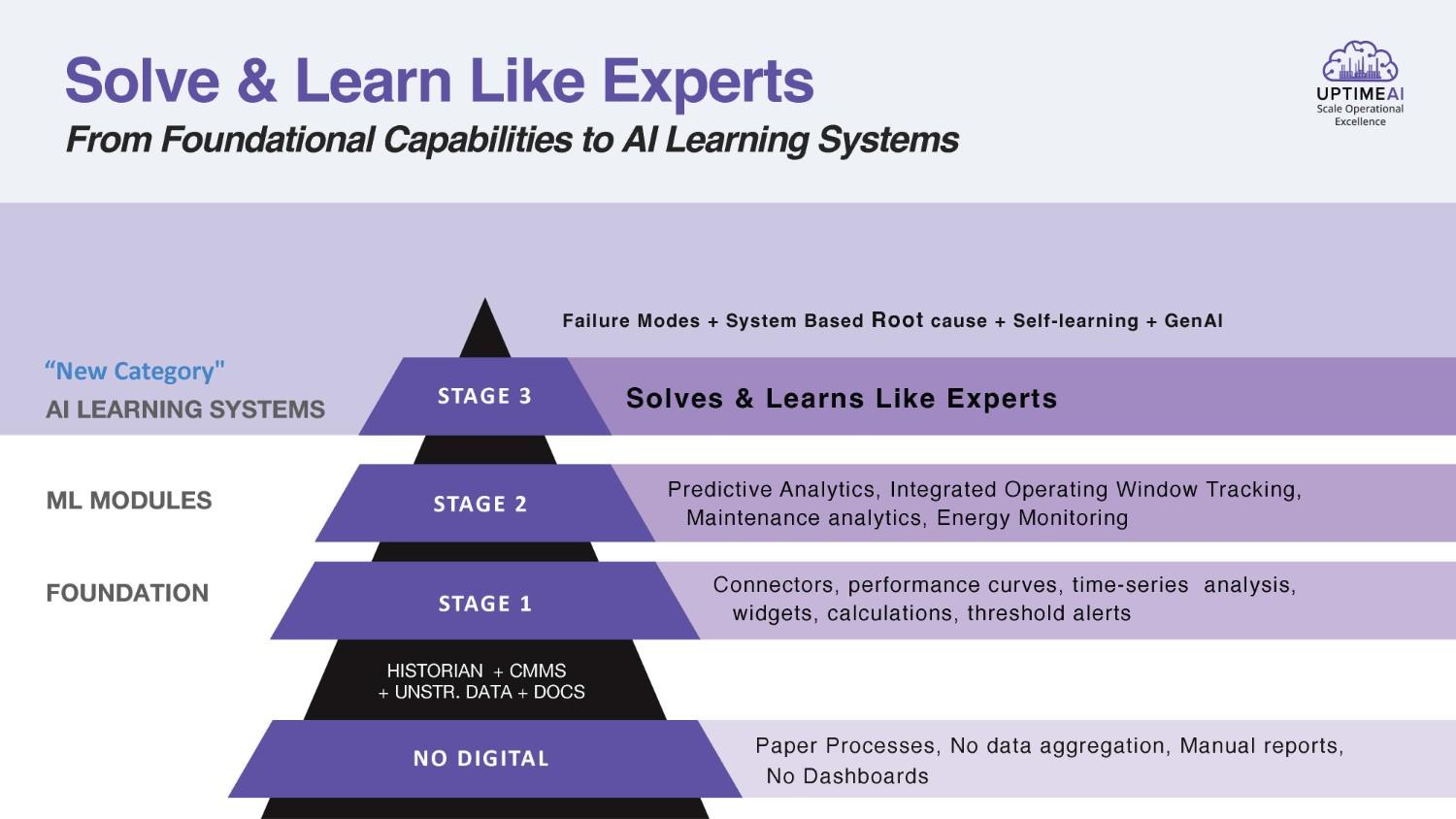
Why do these standalone predictive maintenance tools fail to live up to the hype?
- Most point based AI solutions operate in data silos.
Ex: A vibration sensor might warn that “Motor X is trending high on velocity.” Still, if it isn’t correlated with process conditions (such as a valve downstream slowly clogging), the alert can be misleading or even false. These narrow AI models often lack contextual insight; they detect a symptom but not the cause. - Engineers end up overloaded with disparate tools. You might have one system for thermography, another for lube oil analysis, and a separate reliability spreadsheet for FMEA, and none of them talk to each other. It’s a fragmented approach that makes it hard to see the bigger picture.
- High dependence on Data Scientists to retrain these models, since they must configure them for each emerging issue separately, one by one, draining the productivity of reliability engineers.
The result? Many false positives and alarm fatigue.
Standalone PdM software frequently inundates teams with alarms that turn out to be noise because the tool lacks an understanding of operational context or failure modes. And when an actual failure does happen, the insight often comes too late or not at all.
In short, traditional predictive maintenance tools address individual symptoms but overlook systemic issues, leaving engineers stuck in endless loops, operating in a reactive mode with minimal hope in sight, much like Groundhog Day.
At UptimeAI, we approach reliability from a holistic perspective. Instead of a data analytics software module triggering alerts based on benchmarks, think of UPTIMEAI SME that acts as a central brain, which
- Ingests data from across your plant sensors
- Learning from each alert, guiding your team with actionable recommendations
- And finally, retraining itself based on the actions taken in response to the failure by engineers with zero support from data scientists.
This is the promise of the UptimeAI Expert Operational Excellence (OEx) Platform. By unifying predictive alerts, prescriptive workflows, and that invaluable tribal knowledge which retires with each SME, into one system, a platform-led solution can finally break the reactive cycle. Why?
As the models are built from the ground up based on the context shared and added by Reliability Engineers.
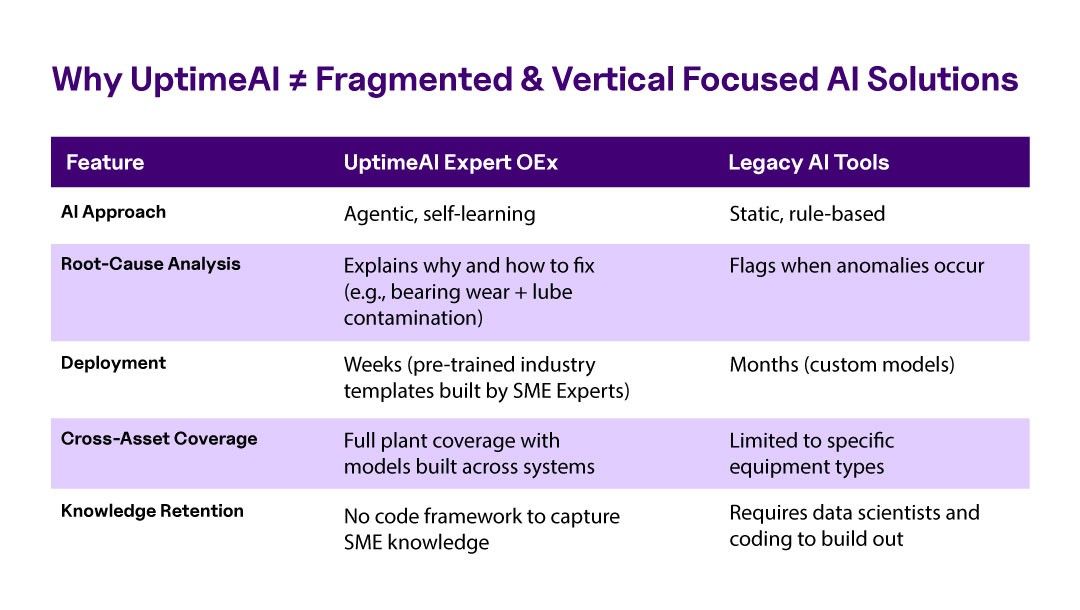
The gaps with legacy AI, PdM & standalone solutions highlight a fundamental truth: addressing reliability requires a holistic view.
If your predictive maintenance approach is a patchwork of point solutions, you’ll constantly run into blind spots and false alarms. It’s like trying to achieve operational excellence with only a few of the pieces visible. This is where the platform approach comes in to connect the dots that standalone tools cannot and deliver value with an agentic approach.
UptimeAI Expert OEx Platform: Delivering Reliability at Scale Across All Sites
UptimeAI delivers enterprise-wide operational excellence, enabling you to achieve AI-driven reliability across all verticals through a single unified rollout, resulting in a positive ROI within one financial year.

Let’s delve into the key capabilities of UptimeAI’s Expert OEx Platform, specifically the modules and features that differentiate this platform-led approach from the traditional way of thinking about reliability. The modules are designed to function like a virtual AI expert team member, tirelessly monitoring, diagnosing, and optimising your plant operation, like a true SME would.
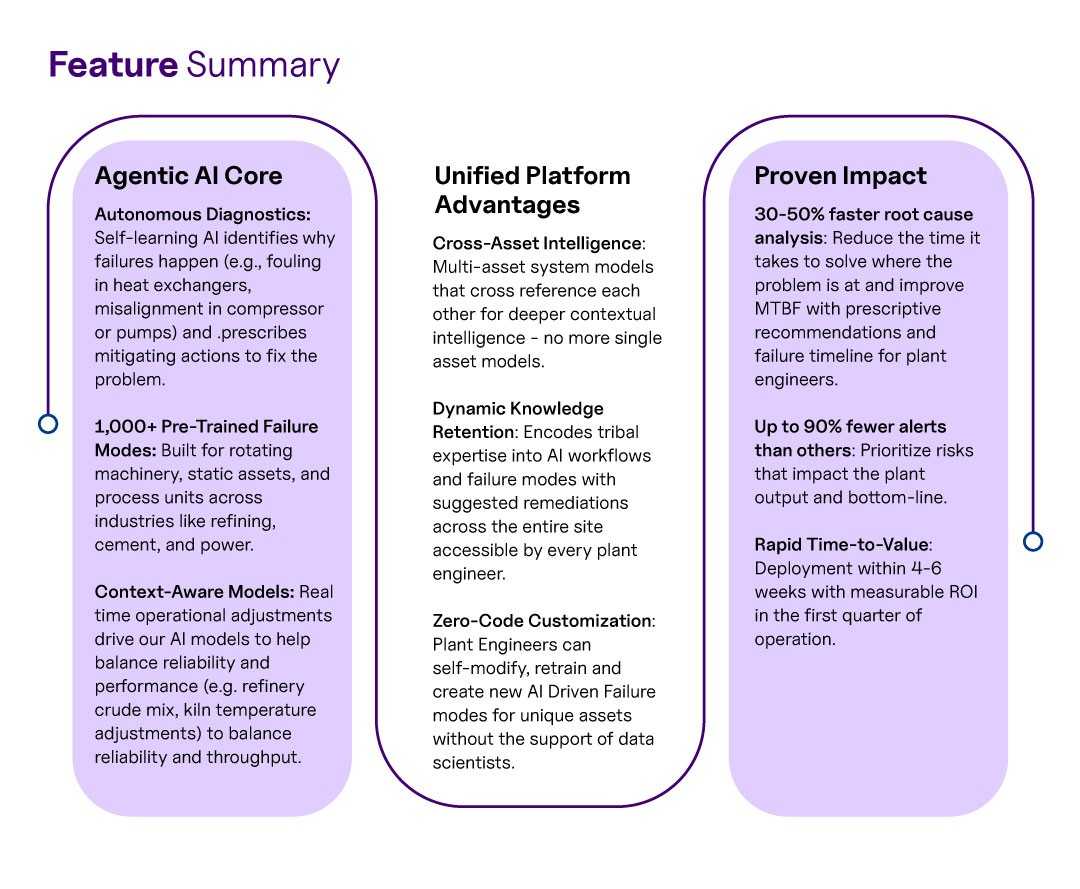
- Intelligent Anomaly Detection (“Detect”): Detecting anomalies early, accurately and suggesting accurate recommendations lies at the core of triggering any alerts.
UptimeAI’s platform utilises advanced, patented AI/ML algorithms that monitor hundreds or thousands of sensors across a system in near real-time. However, unlike basic threshold alerts or simplistic models, this system model approach establishes normal operating envelopes for assets in a bi-dimensional manner. It correlates with the entire process condition, accounting for factors such as load, ambient conditions, and process changes, thereby further minimising the risk of any model drifting.
This helps avoid false alarms while also detecting subtle deviations that precede asset failures by weeks. By scanning across the whole plant and ranking them by significance, you can focus on the ones that truly affect safety, production, or asset health, where the most critical issues are detected and addressed proactively. - Reliability & Process Expert Knowledge Base: The platform features a library of over 1,000 pre-modelled failure mechanisms and behaviour patterns, curated by reliability experts across various industries, including power, refining, chemicals, and cement, with more than 200 years of combined experience. The platform’s Reliability & Process Expert module uses this knowledge to provide immediate context to anomalies. In practical terms, when an alert pops up, it isn’t a cryptic “anomaly score 87% on sensor X.” Instead, it might say: “High vibration and temperature on Compressor B, likely bearing wear aggravated by lube oil contamination (pattern recognised from past incidents).” That insight comes from the failure mode templates in the system. For a reliability engineer, this is gold. It means faster root-cause analysis and fewer wild-goose chases, spending weeks on finding the true cause of anomalies. The knowledge base essentially encodes decades of experience, making it accessible to your team in real-time.
- Agentic-Based LLM ( Gen AI ): Now, with UptimeAI’s GenAI features, you can ask the system questions directly and get answers or reports instantly. For example, you could type or ask, “Show me the root causes of unplanned outages on the ID fan in the past 12 months.” The platform will sift through maintenance logs, historian data, and its knowledge base to answer, perhaps showing a trend chart and noting that three out of four outages were caused by bearing overheating related to cooling pump failures. It’s like having a smart analyst on call. This not only saves time but also makes the system much more user-friendly for folks on the plant floor who may not be data scientists. The ability to query in natural language by reliability engineers lowers the barrier to insight, allowing everyone on the team to harness the power of the data, not just specialists. In an industry where nearly 70% of experienced maintenance personnel are over 50 years old (many of whom are retiring soon), having AI that can democratise expertise and data analysis is a significant advantage.
- Asset Performance Management ( Integrated Operating Window Module ): In today’s industrial landscape, reliability and energy efficiency go hand in hand. Equipment failures and suboptimal operations both lead to energy waste, and with energy costs soaring, this is a top concern. UptimeAI’s platform includes an Integrated Operating Module that could be deployed on standalone critical assets to modify operating parameters & processes for efficiency without sacrificing reliability. A real-world case: the platform detected that a compressor was running hotter than needed at low loads and suggested adjusting its setpoint, which cut that compressor’s energy consumption by a significant margin. Over time, such operational enhancements accumulate to significant cost savings. Consider that inefficiencies, such as equipment fouling or improper controls, can easily waste 10–15% of energy in a given process.
- Scalability and Cross-Site Learning: The platform-led approach enables scaling across multiple assets and even across multiple sites in a single deployment stage. UptimeAI is a cloud-native solution, which means it can be deployed across dozens of plants, learning from all of them. Insights gained in one facility can inform others.
For example, if a particular failure mode is detected in one power station’s turbine, the system can flag other turbines across the fleet to watch for the same pattern. This is a force multiplier for enterprise reliability, it standardises best practices and anomaly detection across all sites. Many companies struggle with variability: one site has a faster RCA-based reliability program while another lags behind. A centralised platform helps raise the bar everywhere by sharing knowledge seamlessly. And deployment-wise, the fact that UptimeAI comes with pre-built templates and does not require heavy data science work for each asset means you can roll it out quickly ( Deployment timelines of 4–6 weeks are achievable, as opposed to the months or more that traditional bespoke solutions take).
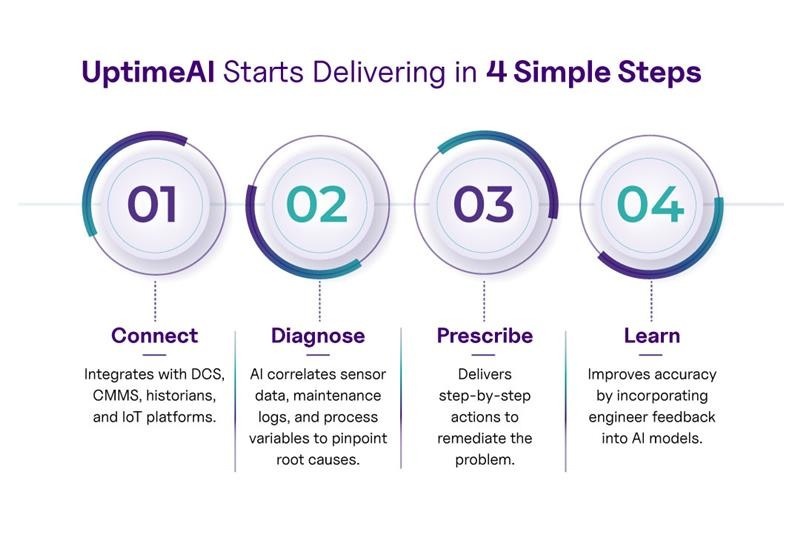
All these capabilities work in concert. The Detect module finds the needle in the haystack; the Expert Knowledge Base explains what that needle means and how it got there; the Failure Mode redommendations lets you learn & retrain the models and understand the whole haystack at will; while Integrated Operating Module ensures you’re not leaving money on the table; and the whole system keeps learning and scaling with your business. It’s a comprehensive toolkit to achieve operational excellence under one solution.

That’s the vision of AIExpert OEx platform in action – an orchestra of AI, data, and human expertise working together to keep the plant operating at its peak output potential. Now stop reacting and start achieving true operational excellence with UptimeAI Expert.