Author: Thomas Lowisz
Title: Senior Product Manager, UptimeAI
Most promising predictive analytics programs hit a wall when it’s time to scale across assets and sites, creating a pressing need for automated model sustainment.
Reliability engineers in heavy industry face a persistent challenge: predictive analytics that work well in pilot programs often struggle to scale across entire plants.
The challenge isn’t the algorithms themselves, but rather the model’s ability to maintain accuracy as equipment conditions change over time. In industry, this phenomenon is commonly described simply as model drift.

Model drift represents one of the biggest barriers to widespread adoption of predictive analytics in the heavy process industries. Understanding the causes of model drift and how recent advances in automated sustainment can address it is crucial for any reliability professional evaluating improvements to their monitoring strategy.
Why Predictive Models Lose Accuracy: Understanding Model Drift in Industrial Context
Predictive models lose accuracy when equipment behavior changes over time. In controlled settings, these changes are gradual, but in heavy industry, they’re constant and complex, risking equipment damage if operators can’t trust the models.

Consider the complexity of the oil & gas industry:
A single offshore oil rig can be equipped with up to 30,000 sensors, though less than 1% of the data is used effectively in decision-making.
In a single compressor, the performance profile shifts with ambient temperature, inlet compositions, downstream pressure, vibration damping effectiveness, and dozens of other variables. This effect is compounded as each operating parameter change to a critical asset can cascade into a performance impact on both upstream and downstream assets.
Each one of these distortions creates what statisticians call “covariate shift” , where the underlying data distribution changes, making historical training data less relevant to current conditions. Without retraining, machine learning models can lose as much as 20% of their predictive accuracy within just 30 days, risking both the investment and perceived feasibility of deploying AI models in heavy industry environments.
The Scaling Economics Problem
This drift phenomenon creates a scaling problem that has fundamental economic implications. A recent survey found that while nearly 50% of manufacturers are piloting AI for predictive maintenance, fewer than 15% have implemented it at scale across operations, with resource constraints being a primary barrier. The mathematics behind this is unforgiving. If each AI model requires 2-4 hours of SME time quarterly for threshold tuning and template updates, monitoring 1,000 assets quickly becomes a full-time job. For most reliability teams, that’s shifting time away from their core focus, from plant operations to model building, which doesn’t help drive operator confidence.

- Coverage: Most successful programs focus on what reliability professionals call “bad actors.” This includes equipment with high failure rates, is a single point of failure for operations, and/or those with a high replacement cost. This focus makes economic sense, but causes smaller, often simpler equipment challenges to be overlooked. While in real operating scenarios, the majority of unplanned downtime events originate from secondary systems that fall outside the traditional monitoring scope. A report from the Electric Power Research Institute (EPRI) validates this, as nearly 45% of industrial unplanned downtime can be traced back to supporting systems like cooling, lube, or secondary pumps.
- Expertise: Reviewing and interpreting an AI-generated alert requires a unique combination of process and equipment expertise, along with data science knowledge. Covering these two domains often means reviewing alerts is a team sport, but the need to call a meeting of various domain experts presents a significant barrier to scaling AI alert systems. As the alert interpretation workload grows, industrial companies are more likely to quiet the alerts by abandoning the technology than they are to hire additional SMEs to interpret alerts.
Why Traditional Approaches Hit a Wall with Scaling
The first generation of industrial predictive analytics was architected around an assumption that proved problematic at scale: that behavior of equipment in a dynamic process environment could be accurately captured in a static model built off a one-time export of historical data. This concept worked out okay for pilot programs, where the focus was on identifying known problems on well-understood equipment within the training data set.

For example, centrifugal pumps that are in constant service, motors with stable loading, and heat exchangers with predictable fouling patterns: when they are provided with clean training data and stable operating periods, these challenges have translated into reliable AI models.
However, when such programs are expanded to include variable-speed drives, batch process equipment, seasonal machinery, or assets with complex interdependencies, the model sustainment burden becomes trickier. With most predictive solutions having hard-coded failure modes with if–then–else rules on sensor tags, flexibility and scalability are further limited.
Each equipment type required specialized knowledge. Each process variation demanded new model recalibration. Each operational change triggers a cascade of threshold adjustments. New challenges for data science teams, or more likely, an additional burden on the operations team to constantly manage 1000s of residual thresholds.
Some data science teams attempt to work around this model drift challenge by manually retraining or cloning models and tightening thresholds on critical assets. While this can defer certain downtime events in the short term, it doesn’t address the underlying drift. In practice, these stop-gap approaches create more SME workload, generate additional false alerts, and often shift stress to other parts of the system, cascading risk rather than preventing it.
This forces the majority of industrial organizations that attempted plant-wide predictive analytics to eventually scale back their programs, with “excessive maintenance overhead” cited as the primary reason.
The Automated Sustainment Breakthrough
Automated Model Sustainment has emerged as a common denominator amongst solutions that have proven successful in full-scale deployments. Instead of treating model drift as a maintenance problem to be solved manually, this proactive approach embeds continuous learning directly into the AI architecture.
Self-Adapting Statistical Models
Rather than static thresholds, automated sustainment uses dynamic learning algorithms that adjust to evolving baselines without human intervention.
Example: When a motor’s current signature shifts after rewinding, or when a pump’s vibration profile changes following impeller replacement, the system recognizes the new normal and recalibrates accordingly.
This isn’t simple parameter tuning; it’s built into the model’s foundation. The algorithms are designed to distinguish between meaningful changes that indicate emerging problems and benign shifts corresponding to new operating conditions. Adaptive AI models using concept drift detection can maintain over 88% accuracy across changing industrial conditions, thus helping to maintain predictive accuracy even as operating conditions evolve significantly.
Economic Transformation of Plant-Wide Coverage
Automated sustainment fundamentally changes the economics of comprehensive monitoring, with the capability to deliver scalable business value impact in the heavy process industries. When models self-maintain or can be re-trained easily with minimal support, the labor cost that previously limited monitoring coverage to only critical equipment disappears.
Organizations can economically justify monitoring every motor, pump, compressor, and heat exchanger in the facility and holistically drive plant-wide intelligence. This comprehensive approach avoids selective monitoring misses that can lead to avoidable unplanned downtime.
In real plant operations, process inefficiencies often manifest first in secondary equipment. Upstream problems create downstream cascades that traditional monitoring approaches don’t connect. Energy optimization opportunities emerge from understanding system-wide interactions rather than individual asset performance.
Organizations deploying plant-wide predictive analytics observed 15–30% improvement in asset utilization and overall equipment effectiveness (OEE), with even higher gains in energy-intensive sectors compared to those monitoring only critical assets. These gains are not credited to individual predictions becoming more accurate, but because comprehensive visibility and understanding enables system-level optimization.
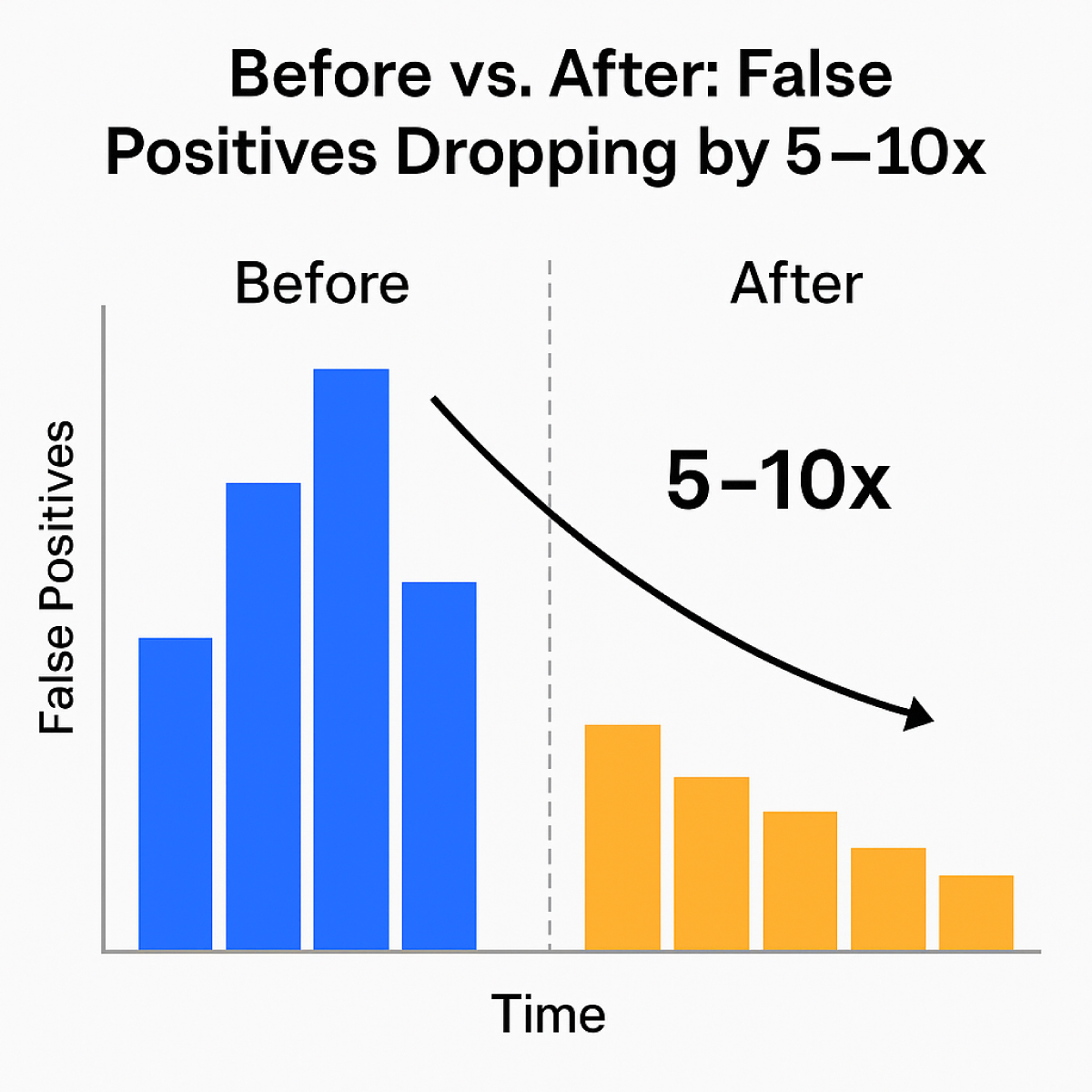
Noise-to-Signal Transformation
Perhaps most importantly, automated sustainment addresses the false positive problem that has plagued industrial AI since its inception. When models stay current with evolving operating conditions, they maintain their ability to distinguish between normal variation and genuine anomalies.
Adaptive models using feedback loops generate 5–10x fewer false positives in maintenance alerts, leading to significantly higher operator trust and response efficiency with corresponding improvements in asset performance.
Beyond Monitoring: Embedded Diagnostic Intelligence Helps Retain Institutional Expertise
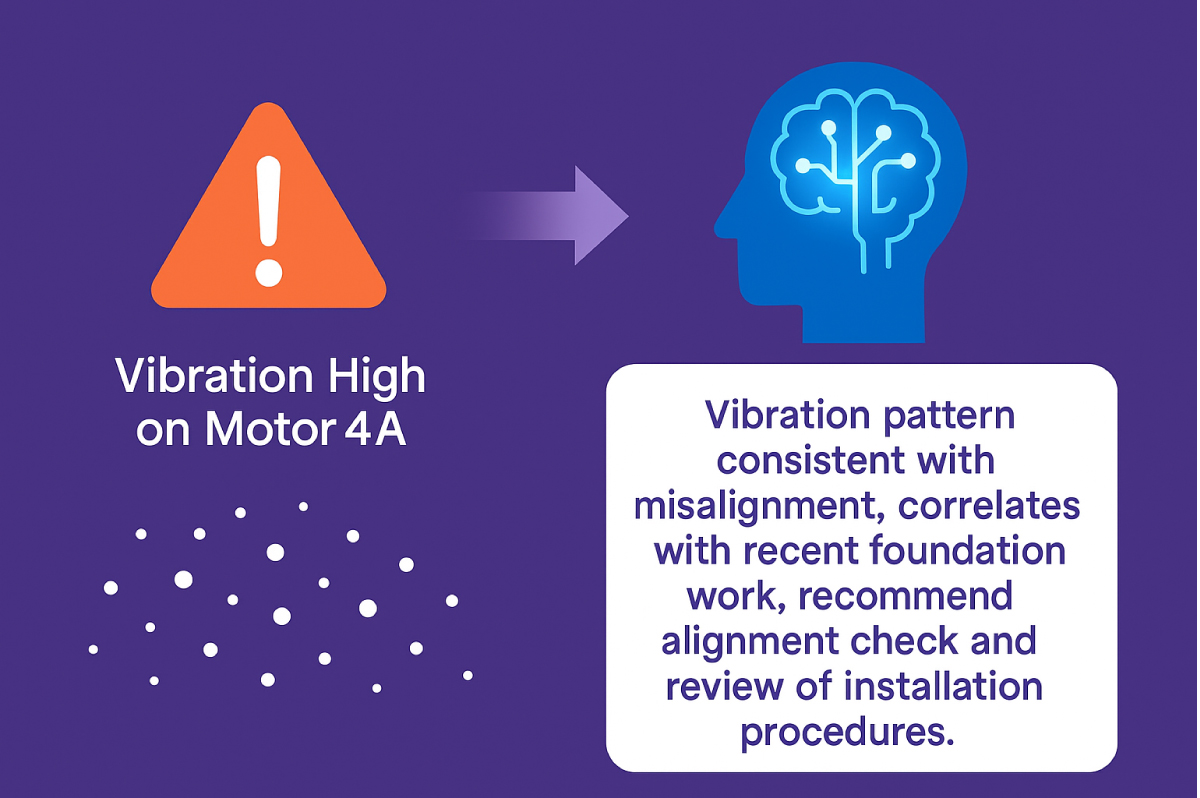
Automated sustainment solves the scaling problem, but modern industrial AI goes further by embedding the diagnostic expertise that reliability engineers typically provide manually.
Traditional predictive analytics stops at the alert: “vibration high on Motor 4A.”
Embedded intelligence continues the analysis: “vibration pattern consistent with misalignment, correlates with recent foundation work, recommend alignment check and review of installation procedures.” Industry-leading solutions also provide reliability engineers the ability to self-train the AI models by passing on the necessary recommendations, encoding critical industry knowledge built over decades.
A Manufacturing Institute report found the exodus of experienced process and equipment experts is a top concern for 78% of manufacturing companies. The self-retraining capability of AI models, powered by domain-specific AI agents trained on decades of reliability knowledge, offers a compelling solution to the existing talent crisis.
The Path Forward for Industrial AI in the Process Industries
For organizations evaluating their future reliability strategy, the question isn’t whether AI will play a role, but rather, can they implement AI that can be self-sustaining at scale.
Industrial companies have an opportunity to gain early adopter advantages and stay ahead of the technology curve. As automated model sustainment makes plant-wide coverage economically feasible, the modelling barriers which have historically hindered the scaling of predictive analytics solutions can be challenged. Reliability Engineers can truly escape the cycle of reactive maintenance issues and drive sustained improvements in reliability, efficiency, and plant-wide operational excellence.
These technical improvements stack up into tangible business value: fewer failures mean avoided production losses, optimized processes cut operating costs, and system-level efficiency boosts output. Together, these benefits make predictive analytics not just an engineering solution but a financial lever, one that can deliver positive ROI within the first quarter after AI project implementation.
UptimeAI is taking advantage of these capabilities and transforming them into an operating system for plant-wide intelligence. Take the first step towards building a foundation for future-proof operational excellence.
